
Тег: php
У Романа Парпалака прочитал про «простейший HTTP-прокси». Ну нет, действительно простейший HTTP-прокси как-то я изобрёл, когда надо было обновить сервер у одного из заказчиков
Очень мне нравится идея навести порядок в функциях ПХП при помощи присобачивания к примитивным типам что-то вроде методов
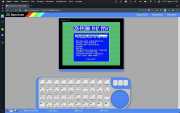

Продолжаю писать о рефакторинге кода, написанного в свой бессонный хакатон. На этот раз хочется избавиться от подобранных вручную координат экрана эмулируемого компьютера — это неаккуратно и не универсально
В ПХП нашли достаточно серьёзный, на мой взгляд, баг — на некоторых повреждённых хешах функция password_verify возвращает true на любой пароль
У меня есть друг, которому я регулярно шлю шутки про «Вархаммер». Сам в этой теме не разбираюсь, но хочется думать, что его они веселят

Вчера ночью чах, в очередной раз, над форматом AVIF — мысль была в качестве эксперимента добавить его в наш документооборот — продукт, разработкой которого я управляю
В «Эгее» есть какой-то плавающий баг, из-за которого иногда не заливаются файлы JPEG. Илья, автор «Эгеи», пытался с ним разобраться, но до конца понять проблему не смог
Затронули тут в одном из айтишных чатов тему десятичной запятой — я считаю, что в русском тексте должна использоваться десятичная запятая, хотя и понимаю
Смотрел недавно исходники языка ПХП, хотел изучить подробнее как реализованы там стримы. Пока читал, случайно натолкнулся на недокументированную возможность — у функции fopen
Немного про программирование
На днях наткнулись на немаловажную особенность, — на системе примонтированной по CIFS (эта система — наследница небезызвестной «Самбы»
В отпуске дошли руки посмотреть и починить баг в функции ucfirst — по задумке она должна приводить в верхний регистр первый символ однобайтовой строки
Обнаружилась очень странная проблема у меня на сайте — некоторые комментаторы стали подписываться с плюсом между именем и фамилией
Очень не хочется это признавать, но похоже тот баг, который я обнаружил в реализации FFI (интерфейса к языку Си
Читая документацию ПХП по модулю «Enchant», наткнулся на неожиданное, для официальной доки, сравнение