
Тег: python
Придумал тут штуку интересную. Как у я уже писал ранее, полюбилось мне что-то писать время с минутами в верхнем индексе
Прям заметно, что эпоха открытого веба закончилась. Было время вокруг были открытые сервисы, используй сколько влезет
Сегодня участвовал в довольно скучной видеоконференции. Моё участие там было хоть и необходимое, но небольшое
xkcd — культовая серия веб-комиксов. Когда-то я их обожал, но потом их перестали переводить, а мой английский в то время было недостаточно хорош, чтобы понимать их без посредников
Тут в чате бывших коллег, где мы постим мемы, пробежала картинка, которая больше повеселила меня не смыслом, который в неё вкладывал автор, а тем, что на системе
У меня есть друг, которому я регулярно шлю шутки про «Вархаммер». Сам в этой теме не разбираюсь, но хочется думать, что его они веселят
Обратил внимание, что мой погодно-пробочный плагин для «Саблайма» сломался — ничего не показывает. Я заметил не сразу, сейчас редко запускаю этот редактор
Продолжая тему интерфейсов к языку Си, кстати будет упомянуть появившийся недавно модуль inlinec для Пайтона
Как я писал в конце прошлого года, есть такое развлечение — не используя алфовитно-цифровые символы, писать осмысленные программы на разных языках программирования
Мы с коллегами сейчас проходим курс по машинному обучению, организованный для нас университетом Иннополиса

Пока сегодня ехал домой с военного поиска (я в таком уже участвовал в прошлом году), написала в «телеграм» дипломница — она не смогла разобраться как сконвертировать в буквы формат постгреса bytea
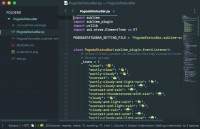
Написал свой первый плагин для «Саблайма» — для отображения в строке состояния погоды и пробок «Яндекса»
Пока отхожу от операции, смотрю сериал «Кремниевая долина» и дабы не заржавел мозг, сделал расшифровку надписи на футболке Эрлиха — одного из героев сериала...
Чудесное нашлось в комментариях на «Хабре»: логичный, на мой взгляд, способ получать значения с конца массива