
Работа над ошибками
Вчера я писал о том как я чуть не прожарил нашу машину с графическими процессорами, а сегодня мы сделали работу над ошибками.
Начали с того, что техники на всякий случай установили больше вентиляторов. Правда, не знаю, помогло ли это чему-нибудь или нет, потому что параллельно я всё-таки разобрался в чём была проблема.

Во-первых, в «Конду» надо было ставить не просто «Пайторч», а специальную версию с поддержкой CUDA, там названия библиотек немного другие. Во-вторых, в «Тензорфлоу» тоже надо было доставить некоторое количество библиотек, сейчас даже не вспомню какие, не записывал.
Почему-то это всё разбросано по целой груде всяких туториалов, так что мне несколько раз по кругу пришлось перепробовать несколько комбинаций. На одну библиотеку я вообще руками создал симлинк с другим именем, не уверен, что это правильный способ, но в спешке выбирать не приходится — хотелось уже побыстрее получить результат.
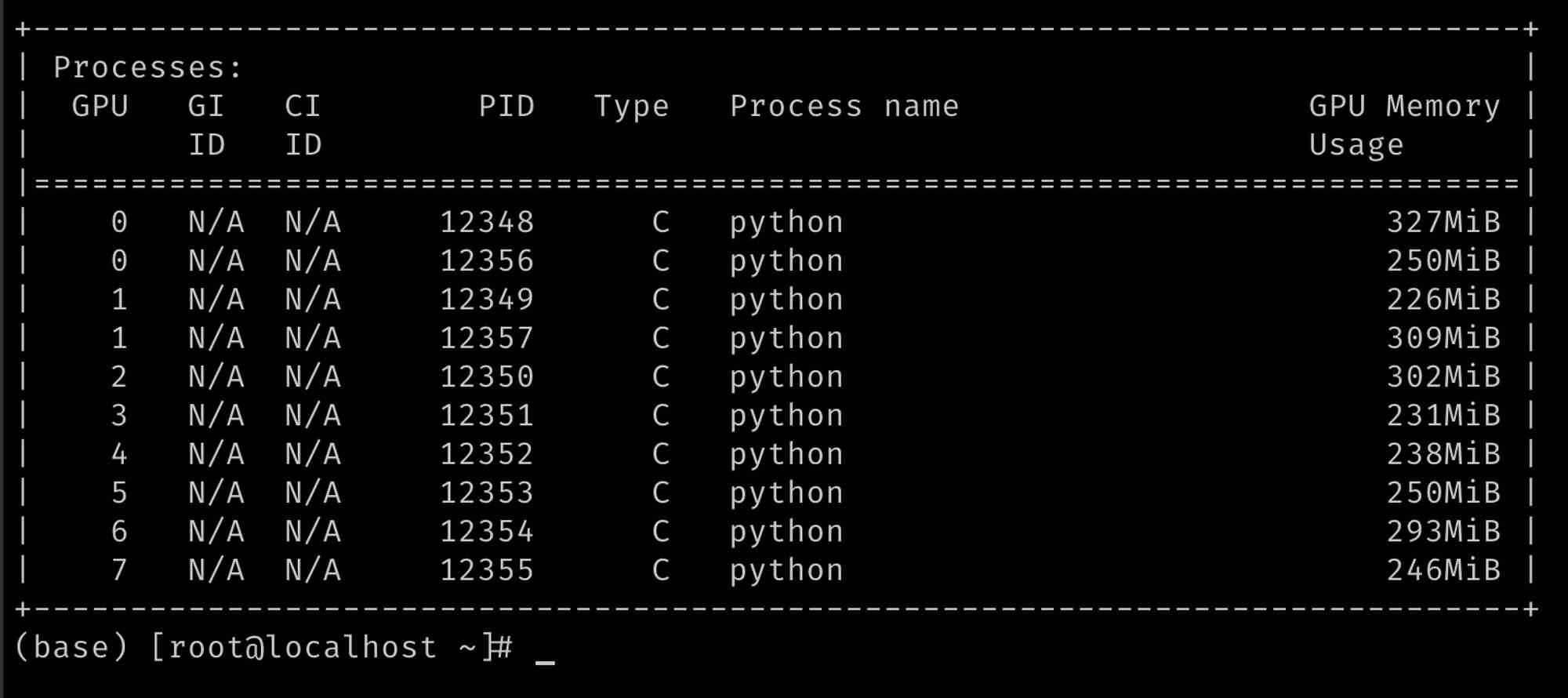
А самое главное — модель и токенайзер нужно было явно перебросить на графическое ядро (там есть ещё какая-то автоматика, но как её правильно включить я пока не разобрался) вызовом метода to. В аргументе указывается cuda: и номер ядра. В моём случае — от нуля до семи.
Это всё отжирает чуть меньше половины памяти одного ядра, так что в параллели удаётся запустить четырнадцать процессов. Возможно, если перейти на потоки, будет лучше, но пока так. Тестировал очень просто:
time xargs -n1 -P14 python test.py < <(seq 0 13)В этом примере моя тестовая программа берёт номер ядра по модулю восемь из первого параметра, таким образом я размазываю запущенное по всем ядрам равномерно.
Четырнадцать процессов параллельно обрабатываются примерно за 40 секунд, один работает примерно за 17, больше половины времени занимает инициализация всего добра и загрузка модели.
Жаль я не смог запустить двадцать процессов — памяти не хватило. Именно с этим числом процессов мне за десять минут почти удалось зажарить центральный процессор.