
Определяем границу символа в UTF-8
В Телеграме попросили рассказать как работает код, который я приводил вчера в заметке про ускорение функции, возвращающей количество символов в строке с кодировкой UTF-8.
Там действительно есть что рассказать, но рассказ придётся разбить на несколько частей. Я постараюсь по возможности не погружаться в дебри. В этой части начну с того, что расскажу чем вообще необычна эта кодировка.
Все кодировки условно можно разделить на две части: кодирующие символ фиксированным или переменным количеством байт. К первым можно отнести, например, CP1251, когда-то широко используемую в ОС «Виндоуз» — там символ кодировался одним байтом, ко вторым — UTF-8, где один символ может занимать от одного до четырёх байт.
Справедливости ради, есть и другие виды кодирования, но нам их рассматривать ни к чему.
Тут важно то, что для строки в UTF-8, нельзя получить её длину, подсчитав количество байт и разделив их на коэффициент хранения. Для каждого байта нам надо понять что он кодирует и считать только те байты, которые отвечают за начало символа. Как это сделать?
Посмотрим на картинку из «Википедии», которая показывает как устроена эта кодировка:
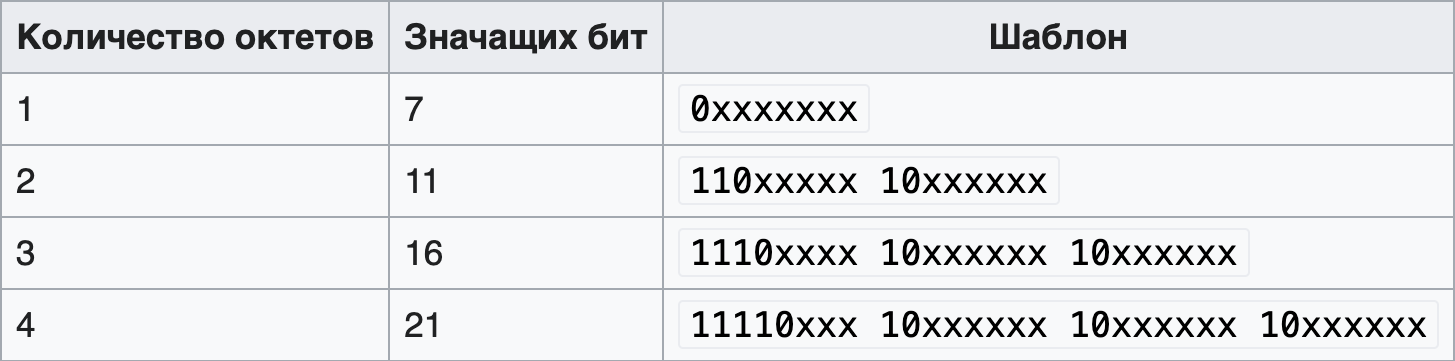
Тут нам интересна только колонка «шаблон», где видно, что все «внутренние» байты символов начинаются с одной и той же сигнатуры — старший бит установлен, младшие — сброшены.
То есть, байты в диапазоне от 10000000 до 10111111 (в бинарном представлении) — внутренние байты, остальные — начало символа. Опять же, согласно таблице начала попадают в диапазоны 00000000-01111111 и от 11000000 до 11011111.
Умные люди заметили одну закономерность, сейчас мы её тоже увидим. Давайте напишем небольшую программу:
#include <stdio.h>
int main() {
const signed char arr[] = {
0b10000000, 0b10111111, 0b00000000, 0b01111111, 0b11000000, 0b11011111
};
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
for (int b = 128; b; b >>= 1) {
printf("%d", (arr[b] & i) > 0);
}
printf(" % d\n", arr[i]);
}
}Вот что она выводит (диапазон, в котором находятся внутренние байты, я выделил другим цветом):
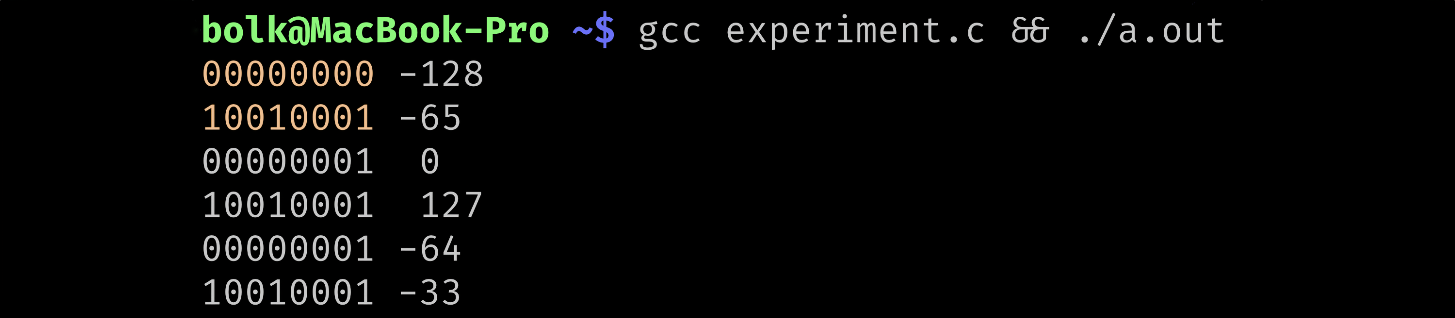
Закономерность в том, что все внутренние байты в знаковом представлении по значению меньше −64. Это довольно дешёвая проверка с точки зрения машинного кода, что очень хорошо, так как наша цель — производительность.
Про остальное — в следующий раз.