
Пилю «Виселицу»
Не то, чтобы я не понимал, что сообщество владельцев «Флиппера» относительно небольшое, всё же это очень специфический инструмент, но всё же не ожидал, что написанная за выходные игрушка удостоится такого внимания.
Только выложил её на «Гитхаб», как мне написал автор одной из популярных альтернативных прошивок, прислал патч, исправляющий некую ошибку и попросил английскую версию, — хочет включить игру в свою прошивку.

Доброе слово и кошке приятно, поэтому вот уже несколько дней пилю поддержку других языков.
Для начала переделал сборку на другой инструментарий — ранее игра не собиралась через более распространённый uFBT, потому что мой код использовал кое-какие кишочки прошивки, а uFBT её не содержит. Такой переход поможет опубликовать игру в общем каталоге, но я с этим не спешу.
Для поддержки английского пришлось довольно много переделать, всё что осталось сейчас — вывести меню, наверное сегодня уже доделаю. Я замахнулся на конфигурируемую поддержку, по моей идее, можно будет очень просто добавить любой язык, для которого есть шрифт.
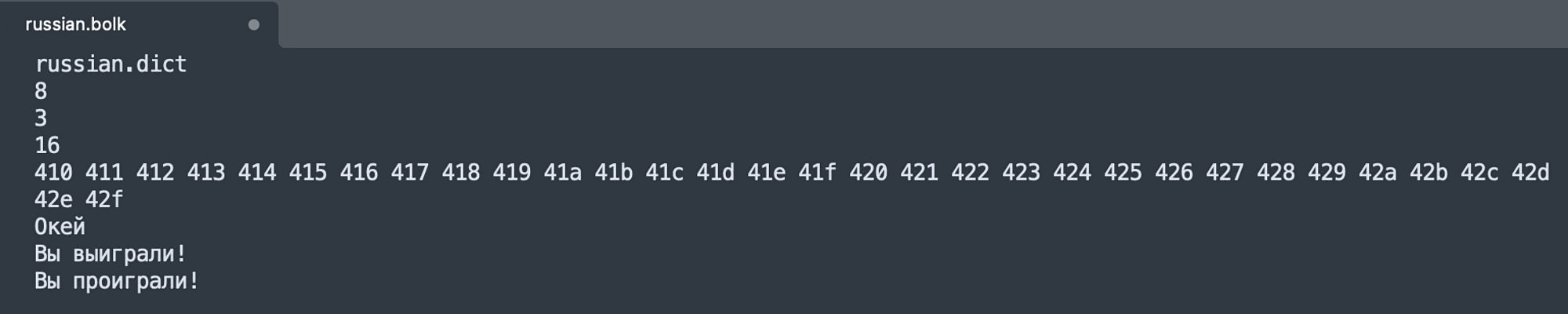
В итоге, файл описания выглядит как текстовый файл, где первой строкой написано название словаря, ниже стоит цифра, показывающая сколько букв будет выведено в строке, при рисовании клавиатуры, ещё ниже — зазор между буквами в угадываемом слове в пикселях, потом цифра, про которую я расскажу дальше, ниже — шестнадцатеричные коды букв в кодировке UCS-2, ещё ниже — строки сообщений.
Если открыть словарь для английского языка обычным текстовым редактором, то внутри будет текст, с русским такой номер не пройдёт. Объясню почему.
Когда я только начал программировать игру, начал я с упаковки русского словаря в программный код и генерации случайного слова. Оказалось, что быстро выбрать случайное слово не так-то просто. Первый вариант работал очень медленно, поэтому я сделал оптимизации, которые мне помогли достичь комфортной скорости.
Во-первых, я перешёл на другой генератор — встроенный вызов furi_hal_random_get() вместо обычного для Си random(). Друг, который в прошлом имел дело с микроконтроллёрами, сказал, что как правило лучше использовать то, что предлагает фреймворк — так быстрее.
Во-вторых, я переделал метод выбора случайного слова. Раньше я выбирал слово с линейной сложностью — генерировал номер строки и читал словарь, пока его не достигну. Переделал на константную — выбираю случайное смещение в файле и ищу следующее слово после него. Что дало теоретический положительный эффект — более длинные слова выбираются чаще.
В-третьих, почти в два раза сократил файл словаря. Любая русская буква занимает в распространённых юникодных кодировках два байта, но второй байт всегда одинаковый, его можно выкинуть. Если посмотреть на ряд, описывающий клавиши в моём файле, видно, что первая четвёрка всё время повторяется. То есть из кода русской буквы А — 0x0410 можно убрать 0x04 и оставить только 0x10, мы и так будем знать какую букву кодировать.
В словаре так и сделано. Поскольку внутри программы я храню различные состояния в виде массива, мне нужно знать минимальный получившийся код символа, чтобы вычитать его, преобразовывая код в смещение в массиве. Для русского языка минимальный код будет у буквы А — 0x10, как я показывал выше, то его и нужно записать в файл описания языка. Цифра 16 в нём — это и есть 0x10 в десятичной кодировке.
Надеюсь сегодня допишу всё что нужно и выложу новый вариант.