
ARM бывают разные
Преодолев внутреннее сопротивление, я всё-таки занялся переносом векторизованной функции измерения длины строки на «Флиппер Зеро». Почти сразу выяснилось, что моя интуиция меня не обманула — на этом пути куча проблем.
Во «Флиппере» стоит процессор ARM, а они, как оказалось, бывают очень разные.
Я ещё в самом начале посмотрел спецификацию процессора «Флиппера» и, увидев слово SIMD, совершенно успокоился — в моём понимании это означало, что я могу использовать любые команды векторизации, которые мне необходимы. Тут я немного поторопился, но меня подгоняло желание разобраться как устроена векторизация. Теорию я знал, а тут подвернулась, пусть немного синтетическая, но задача, которую руки чесались решить.
Как я уже говорил, мне захотелось срезать углы, поэтому функцию до этого момента я писал на своём ноутбуке, раз так случилось, что у меня на нём тоже процессор ARM. И лишь сегодня я попробовал вставить её в одну из своих программ и собрать её для «Флиппера».
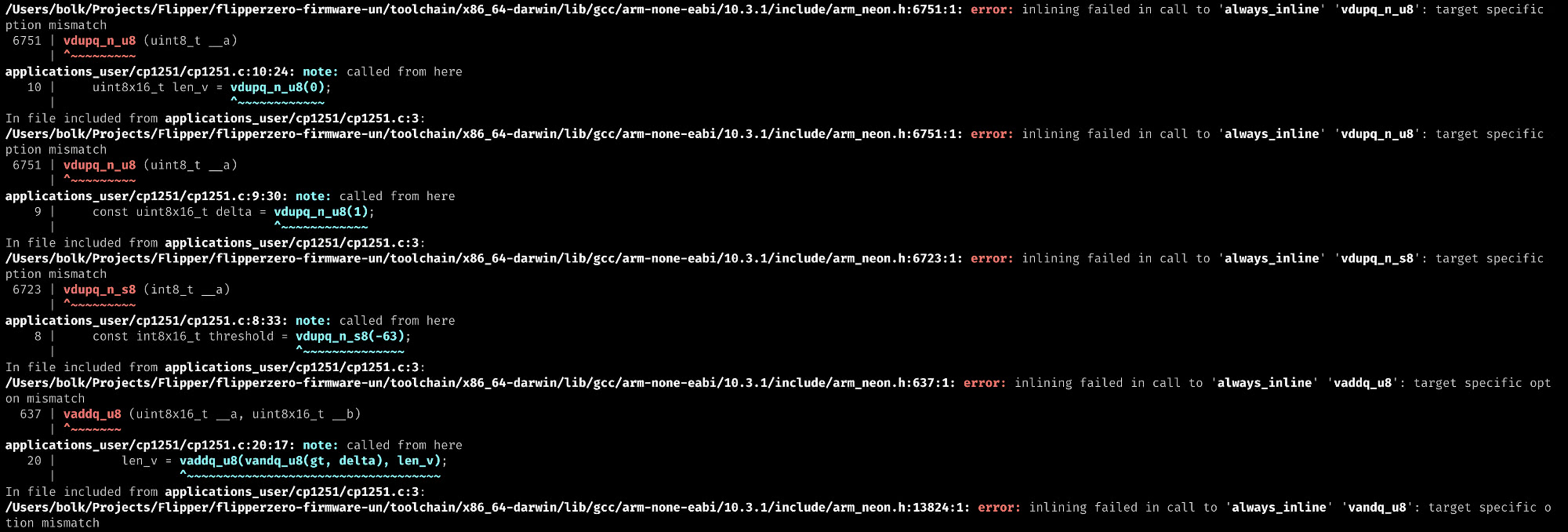
Сначала компилятор заявил мне, что не нашёл некоторые векторные функции, в частности функцию нахождения минимума vminvq_u8 и суммы vaddvq_u8.
Ветку с vminvq_u8 я временно убрал, а функцию суммы vaddvq_u8 решил заменить на поэлементное сложение (vaddq_u8), которая, вроде, компилятору знакома.
Мысль простая — в векторах, сумму которых мы находим, на каждой позиции нули и единицы, поскольку каждый элемент вектора у нас восьмибитный, в общем случае у нас поместится результат 255 операций, а потом я могу просто просуммировать элементы циклом. Как-то так:
uint8x16_t len_v = vdupq_n_u8(0);
int reset = 0;
// тут у нас цикл
uint8x16_t gt = vcgtq_s8(operand, threshold);
len_v = vaddq_u8(vandq_u8(gt, delta), len_v);
if (++reset >= 255) {
for (size_t i = 0; i < sizeof(uint8x16_t); i++) {
len += *((uint8_t *)&len_v + i);
}
reset = 0;
len_v = vdupq_n_u8(0);
}Я был очень доволен решением (оно не совсем моё, его мне навеял код, используемый в PHP), но оказалось, что оно тоже не компилируется.
Сборка заругалась на ошибку target specific option mismatch, означающую, что указанное при компиляции железо не поддерживает те возможности, которые я пытаюсь использовать в коде. Пришлось лезть в тулчейн, чтобы разобраться какие ключи компиляции сейчас используются.
В файле compile_commands.json можно увидеть, что при сборке используется ключ -mfpu=fpv4-sp-d16, тогда как мне, чтобы использовать нужные команды векторизации нужен ключ -mfpu=neon.
Так как ключи компиляции указывали разработчики «Флиппера», думаю, они в точности знали в какие значения их выставить. Согласно спецификации на борту использованного во «Флиппере» процессора SIMD есть, но, видимо, какой-то другой. Так как SIMD написано в разделе DSP Extension, надо смотреть что это такое, может всё-таки можно использовать эти команды для ускорения.
Вот совсем не факт. Всякое может быть (хотя на продвинутый процессор в таком устройстве я бы не рассчитывал). А у процессора можно спросить, кто он на самом деле и что он умеет?
Думаю, что можно, но в спеке NEON всё одно не упоминается. Зато я разобрался что за DSP SIMD такой. Векторных операций там, конечно, кот наплакал, да и вектор в два раза меньше, чем у NEON, но для интереса попробую что-нибудь написать. Если не удастся найти операцию, которая быстро определяет, что в векторе есть ноль (конец строки), то это гиблое дело, конечно.