
Как скачать документ из АИС ЦГАСО-3
Архив ЦГАСО несколько изменил у себя вёрстку и предыдущий способ скачивания работать перестал. Сегодня мне понадобились документы из этого архива, пришлось посмотреть в чём дело.
Для того, чтобы скачать листы дела, вам нужно в браузере (настоятельно рекомендую «Хром», в других браузерах я код не испытывал) перейти в раздел «Требования дел» и открыть на просмотр нужное вам дело (для этого нужно нажать на значок «книжки» в колонце «Действие»).
 |
Когда дело откроется, нужно открыть панель разработчика (открывается по Ctrl+Alt+I на «Виндоузе» или Cmd+Alt+I на «Маках») и там перейти во вкладку «Консоль» (Console). В этой вкладке вставить нижеприведённый код и нажать «Энтер».
!function () {
var id = '[id=storageFilesViewerPnl]';
var bt = '[id$=ForwardBtn]';
var pages = {};
var o = document.querySelector(id);
!function _observe(undefined) {
var ob = new MutationObserver(function() {
var imgs = $(id+' img[src*=Pages]:first');
if (imgs && imgs[0]) {
var page = imgs[0].src.match(/id=([^&]+)/)[1];
if (pages[page] == undefined) {
pages[page] = true;
ob.disconnect();
var next = $(bt);
if (next && next[0]) {
_observe();
next[0].click();
} else {
console.clear();
console.log("dxo.itemsValue=['" + Object.keys(pages).join("','")+"'];");
}
}
}
});
ob.observe(o, { childList: true, attributes: true, subtree: true, attributeFilter: ['src'] });
}();
o.setAttribute('src', true);
}();Начнётся пролистывание документа. Запаситесь терпением. Как только оно закончится, на экране появится длинная строка, как на скриншоте ниже. Её надо скопировать в файл целиком.
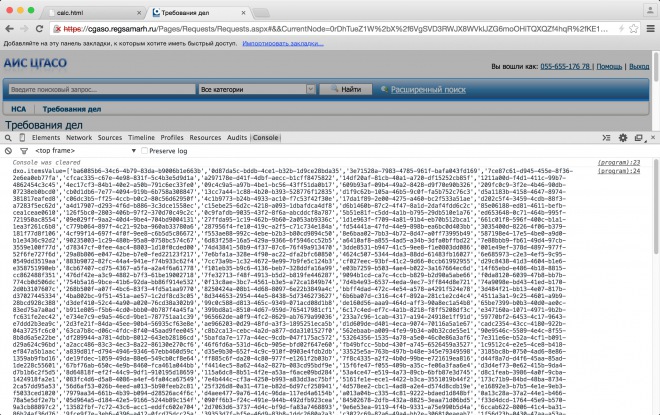 |
Далее, увы, вам придётся занять компилированием. Как это делается, рассказывать не буду, ищите в интернете. Вам понадобится программа cgodownloader.go из моего репозитория, её надо сохранить к себе на диск и скомпилировать (она написана на Гоу). Ей на вход надо передать имя файла (в моём случае это 150-1-120) и директорию, куда будут сохраняться картинки листов дела (у меня это 150-1-201-pict):
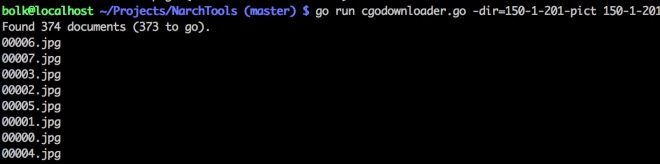 |
Когда программа закончит работу, в указанном вами директории будет лежать дело целиком.
Спасибо огромное! Ждал, и таки дождался этого поста!)))
В winxp, win7 если страниц несколько тысяч хром валится в диапазоне 500-700 страницы с ошибкой.
В Mint 17 еще попробую
До 400-500 свободно проглатывает
От меня тоже огромное спасибо
Большое Вам спасибо!
Кстати да, после 500 страницы хром почему-то виснет напрочь.
Комментарий для Василий:
«Винды» у меня нет, поэтому сказать почему виснет я, увы, не могу.
p.s
В Minte дело 2700 листов хром завис напрочь после 920 стр.
Я так понимаю не хватает памяти
В xp увеличил файл подкачки освободил больше места на с: — ноль эмоций
Комментарий для Kraut:
Очень странно, 2700 значений это не очень-то много. Можно вот так попробовать:
http://pastebin.com/eQ90xJSn
Так как?:) Я заинтригован, а коммент не дописан.
Оперативку просто адово ест, кстати.
Комментарий для Василий:
Как не дописан? Там код приведён.
Комментарий для Василий:
Если у Вас Мозилла с Noscript, то разрешите pastebin.com, сам только что разобрался.
Ну у меня это вот так вот выглядит — кода не вижу.
https://fotki.yandex.ru/next/users/non-alcoholic/album/468891/view/1472979?page=0
Комментарий для Константин:
Вот именно что в трех браузерах просмотрел, антивирус отрубил и все равно ничего не видно. и носкрипта у меня нет. Заговор какой-то:)))
Все — нашел в коде страницы ссылку на пастбин. Сейчас буду пытаться туда зайти.
А он не работает — видимо, временные неполадки.
Константин, новый скрипт помог решить проблему?
Комментарий для Василий:
К сожалению, самое длинное дело на сегодня — 153 листа, постараюсь проверить на след. неделе. Скрипт рабочий.
В xp пробовал с новым скриптом, с обновленным флешем (выскакивало окошко обновления), с новым профилем в хроме, запускал прогу очистки памяти (сначала вроде бы помогало, но потом физическая память приблизилась к 99% и 3,4гб и снова завис браузер) — бестолку
Если увижу у себя проблему, буду править. Но у меня не Виндоуз, проблем пока не наблюдаю.
На компе с 8 гб оперативки все скачалось — видимо, дело в ее объеме и прожорливости скриптика:)
Комментарий для Василий:
Возможно, я просто не вижу что могло бы так есть память.
у меня в хроме после ввода скрипта в консоль пишет просто true. тобольский архив. у кого-нибудь пробовал на тобольском?
Плохо знаю JS, но может быть проще понять как по странным значениям из dxo.itemsValue (которые похожи на base64) получить ту GUID, которые на самом деле имена файлов с листами из дел?
Я немного покопался в коде. Видно, что такие псевдо-base64 там используются массово. Не только для сокрытия имён файлов. Если посмотреть на эти строки псевдо-base64 (например ’QNy9j9FDYhfSNXZw4XiMvt7tql8kfe+LcsnM7XIDbd/gHLlYD6Lm2g==’), то видно, что набор символов не отличается от стандартного base64. Причём все такие строки равны 56 байтам. Исходя из того, что base64 кодирует как 4:3 видно, что исходная строка равна 42 байтам. Если принять во внимание финальные == (добавленные для выравнивания), то на самом деле исходная строка всего 40 байт. Что сильно больше GUID, который надо закодировать (16 байт или 32 байта если записывать хексами или 36 байт если считать и разделители).
Я сравнил несколько GUID и соответствующие им псевдо-base64-строки. Между ними явно нет соответствия. То есть это не base64 с заменой символов. Тут или просто использование большого словаря соответствий между GUID (именами файлов) и псевдо-base64-строками. И тогда никакой закономерности и не будет. Или же кодируется GUID, разбавленный по неизвестному алгоритму каким-то мусором.
Не пробовали понять как генерируется код страницы при переходе на другой лист? Многие функции обфусцированы и под отладчиком ходить не очень удобно. Но может быть есть там где-то функция, преобразующая псевдо-base64-строку в GUID? Или же такое преобразование делается через вызов какой-то функции с сервера? Тогда сам алгоритм преобразования нам и не нужен, достаточно дёргать соответствующую серверную функцию и не придётся листать всё дело.
Комментарий для ml:
Нет, не пробовал.
Всем привет!
Значит решил я применить Вашу схему к Тюменскому архиву http://109.233.229.20:81/Pages/Main.aspx
Схема незаработала на этапе компиляции, создала кучу джпегов, которые по сути были html с информацией об ошибке...
Начал изучать код, и понял, что строка запроса несколько отличается от исходной, да и хост не тот.
Было:
const url = ` http://%s/Pages/ImageFile.ashx?level=10%26x=0%26y=0%26tileOverlap=1024%26id=%s%26page=0%26XHDOC=%26archiveId=1%60
const defaulthost=«cgaso.regsamarh.ru»
Сделал:
const url = ` http://%s/Pages/ImageFile.ashx?level=10%26x=0%26y=0%26tileSize=256%26tileOverlap=1%26id=%s%26page=0%26rotation=0%60
const defaulthost=«109.233.229.20:81»
В итоге качались только первые куски с координатами по х/у 0/0. А потом и вообще сайт архива застрелился. =)
Service Unavailable
HTTP Error 503. The service is unavailable.
Подождём-с когда поднимут, да послушаем мнение авторитетных товарищей. Что скажите?
Комментарий для Volhvuk:
Лично я — ничего не скажу. Тюменский архив я не использую и не планирую.
Уважаемый bolknote.ru, если взялся за гуж, не говори что не гуж, не набивай себе цену, не к лицу, скажи в личку, что надо, и сделай для Тюмени, мне жалко времени своего для копирования(принкринов), у меня 6 деревень, в каждой деревне по 10 книг, и это мое древо, и злого умысла не вижу, пишу в фейсбук, не отвечаешь. Ведь главное в жизни это результат, а его пока нет, только куски и никакой конкретики, удали тогда свой пост, смысл с него, если ничего не понятно, а желания объяснить нету, проблему не в том, что народ тупой, проблема в том, что наставник из тебя никудышный.. Evgesha(scorpion_dev@mail.ru)
Комментарий для Evgesha(scorpion_dev@mail.ru):
Я не собираюсь кого-то учить, наставлять или просвещать. Всё это я делаю для себя, блог веду тоже для себя. Если кто-то пользуется результатами моих трудов, я не против, но и только.
Что за бред? Почему я должен в своём блоге что-то удалять?
Комментарий для Volhvuk:
Нда, грубовато конечно Евгеша =)
И всё же, я думаю принцип работы в обоих архивах одинаковый, так как один и тот же софт у них стоит. Евгений, хотел вас попросить глянуть, что я не так делаю...
Общая картинка состоит так же из кусков с координатами x / y
Но у меня почему то скачивается только первый кубик с координатами 0/0, а приклеивания других кусочков не происходит.
НО, разобрался сам =) Спасибо. Вот только не пойму зачем они собирают мозайку из кучи мелких обрезков одного и того же файла, ведь по сути обращаются к одной и той же картинке. Они сами себе сервер перегружают запросами, только ради того, что бы запутать людей =)
Volhvuk если получилось, помоги другим, про кубики с координатами, давно увидел, и вина тому насколько понял не архив и ПО, а браузеры, чтобы наоборот увеличить скорость загрузки, за счет многопоточности.
А на счет высказывания это не грубо, а правда, не люблю лебезить,
Искренне считаю, если человек знает, всегда скажет что не так, хоть ночью разбуди, а здесь одна показуха, я разработчик, но типа я не консультирую, да бред это,
Вот если я сейчас знаю, то и могу рассказать свободно. как и чего достиг:
Операционная система Windows профессионал, 7, 64
Зашел на сайт архива http://109.233.229.20:81/%28%D1%83 меня есть предварительная регистрация)
выбрал архив с 5 листами(маленький для пробы)
На ПК уже предварительно установлен ХРОМ, согласно требованиям разработчика
Из поста > Как скачать документ из АИС ЦГАСО-3
скопировал текст программы и выполнил рекомендации
получил данные, сохранил файл
Взял из репозитория, указанного в этом же посте взял программу и файлы, скачал в отдельную папку
Установил GO?
а далее как раз затык, что надо сделать
Вот о чем речь
а вот далее все опять более менее понятно
скачиваем программу и устанавливаем Sublime Text 3
открываем cgodownloader.go,через правую кнопку мыши
правим строки
согласно поста Volhvuk
в этой строке пишется размер шрифта и разрешение, 10 и 1024 соответственно
А вот дальше я не знаю, раз владелец не хочет консультировать, жду жаждущих, чтобы совместно одолеть этого зверя
В общем всё оказалось просто. В коде автора, дай бог ему здоровья, нужно исправить:
« http://pastebin.com/raw.php?i=VamLswki%22
В общем всё оказалось просто. В коде автора, дай бог ему здоровья, нужно исправить:
« http://pastebin.com/VamLswki%22
Одно не пойму, почему после долгого сканирования, при попытке скачать у них вылетает ресурс, у них и заодно архив Тобольской области, видимо они на одном сервере.
Не хочется доставлять работникам архива неудобства.
И ещё, уважаемый Евгений, подскажите пожалуйста, ваша программа качает в несколько потоков одновременно? Можно регулировать количество потоков, например сделать равным 1 ?
Программа отработала, но файлы в директории не появились
Во первых. Вы неправильно компилируете. Сначала нужно скомпилировать и создать исполняемый файл *.exe.
Во вторых скармливать нужно строкой вида:
C:\gopath>cgodownloader.exe -dir=pikt-150-1-124 150-1-124.html (или txt)
Комментарий для Volhvuk:
Да, можно. По-умолчанию, работает на скачивание количество потоков (горутин) равное удвоенному количеству процессоров. Это строка N := runtime.NumCPU() * 2. Замените её на N := 1
Комментарий для Евгения Степанищева:
Спасибо! А то я чувствую, что 16 потоков многовато =)
Комментарий для Евгения Степанищева:
Евгений поясни, почему иногда после запуска, сохраняются только названия файлов, с размером 0, а иногда, этот же файл сохраняется нормально
Комментарий для Evgesha(scorpion_dev@mail.ru):
Поддержкой программы я не занимаюсь.
Пробовал на последней версии Хром на разных машинах. Доходит до 40-70 страницы и вываливается с вот этим:
что бы это могло быть?
Комментарий для Евгения Степанищева:
«На последней версии Хрома», а не «Хром».
Что это такое — сказать трудно, судя по ошибке, сработала какая-то защита безопасности в браузере. Если столкнусь с этой ошибкой — разберусь, по описанию, увы, не скажу что это.
Ну да, у меня ляпы бывают.
Проверил в Firefox: стоит, как статуя, страницы не листает. В Опере — работает!
Иногда встречаются дела, где число файлов в списке больше числа страниц. Глюк какой-то. Вот на них скрипт бесконечно ходит по кругу и массив для скармливания скачивателю не формирует...
Жрет физич. память не скрипт. В Win.7, Chrome при генерации изображений ЭЛАРом каждое последующее изображение сохраняет в оперативку. Это легко проверить... не запуская скрипт прощелкать 1000 изображений в ручную :-) и у Вас хром так-же вылетит с ошибкой.
Вопрос что делать? ...каким то образом выгружать данные из оперативки на HDD или настроить хром чтоб не сохранял в памяти просмотренные изображения... но как? Есть идеи?
Проблема решилась увеличив файл подкачки до 12Гб (оперативки 8Гб)
Оперативку думаю жрёт всё таки скрипт — там рекурсия!!!
Комментарий для Дмитрий:
У этой «рекурсии» вложенность равна единице.
Написал Эксель на языке VBA, который на данный момент умеет скачивать единичный файл (тюменских архивов) из квадратиков и склеивать их.
Теперь хочу, чтобы он умел скачивать дела целиком.
Хотелось бы чтобы VBA в режиме реального времени а) определял id картинки следующей страницы б) скачивал ее в) возвращался к а) пока листы в деле не закончатся.
Есть идеи как это сделать?
Комментарий для LuckyLuke:
У меня что ли? Нет, никакого желания задумываться об этом.
Евгений, я уже разобрался!
По поводу работы консоли, думаю, если сразу после кэширования id остановить загрузку страницы (получение данных), процесс перелистывания дела будет намного быстрее.
К сожалению сам не умею такого написать.
Комментарий для LuckyLuke:
Где это, у меня нет там никакого кеширования id
Как только нужное получено, сразу начинается загрузка следующей страницы, это, естественно, останавливает загрузку предыдущей
Нет предыдущая продолжает загружаться пока не начнет загружаться новая, а это происходит со значительной задержкой, думаю, как раз из-за того, что продолжает загружаться старая.
Комментарий для LuckyLuke:
Нет, не из-за этого. Из-за задержки сети и длительности ответа сервера.
Идет кеширование страниц... не знаю как, но факт на лицо. Отсюда переполнение оперативки и как следствие вылет хрома с ошибкой после 500-800 стр. Если свернуть браузер в маленькое окно нажать просмотр документа и запустить скрипт, процесс перелистывания страниц идет намного шустрее, нет ошибки...
В последнее время документ невозможно скачать в глубоком разрешении... в чем причина не знаю, но при открытии инструмента разработчика стала вылетать ошибка https://cgaso.regsamarh.ru/javascript/suggest.js?tstmp=2015-02-19-12-12 Failed to load resource: the server responded with a status of 404 (Not Found)
p/s Windows 7
Евгений, кажется, ЦГАСО опять перестроил формат данных, и всё снова перестало скачиваться
Комментарий для Ку:
Жаль. Если мне в этом архиве что-то ещё понадобится, буду смотреть.
Будем ждать с огромной надеждой...
Очень будем ждать...
В чем проблема? Скрипт вроде работает...
Да, теперь скачиваются пустые jpg. Вся надежда на Вас.
Комментарий для Urator:
Пока мне в архиве, увы, ничего не нужно. Да и логин мой отчего-то перестал работать.
Комментарий для Евгения Степанищева:
Скорее всего закончился годовой доступ.
Временное решение в самой качалке заменить строчку на
const url = ` http://%s/Pages/ImageFilePart.ashx?Crop=False%26id=%s%26Page=0%26Zoom=1%60
Иван молорик, все верно. Почему временное... Разрешение (глубину) изображения можно изменить параметром Zoom от 0,1 до бесстыдно глубокого.
Комментарий для Alex (Иван):
Да нет, я недавно оформлял новый. Но у меня какие-то перебои с доступом — пускает не с первого раза.
А кто нибудь пробовал качать с Ярославского архива?
Комментарий для Urator:
В тобольском архиве тоже однажды стали качаться только пустые jpg.
Снова обновили АИС и все упало
Увы, да. Но я сейчас не работаю в этом архиве — нужды нет, поэтому не переделываю программу.
Здравствуйте.
Существует ли на данный момент рабочий способ скачивания дел из Самарского архива?
Увы, проект я забросил — в архиве Самары у меня сейчас нет интересов.
Может все же сможете помочь в этом деле? Я думаю, что много кому своей программкой поможете.
У меня сейчас нет никакого мотива это делать.
Добрый день, и с Праздниками!
Огромное спасибо за Ваш труд, несколько раз очень выручал.
Сейчас АИС архивы переходят на шифрование (https) и скачать ну никак не получается, скачиваются страницы с просьбой авторизоваться (шапка ниже). Никак не могу придумать, как запустить код на скачивание прямо из консоли браузера, после авторизации. Данной проблемой никто в рунете больше не занимался, поэтому вся надежда на Вас =)
<!DOCTYPE html>
<html xmlns=«http://www.w3.org/1999/xhtml»>
<head id=«Head1»><title>
Вход в систему АИС ЭЛАР-Архив
</title><meta http-equiv=«X-UA-Compatible» content=«IE=edge» /><meta http-equiv=«Pragma» content=«no-cache» /><link rel=«SHORTCUT ICON» href=«images/elar.ico» /><link href=«/Content/styles?v=UTluiiAofnuLMUIZfmCJWysnk0l5PYxT_aI6RY_vkag1» rel=«stylesheet»/>
<link href=«/Content/themes/base/css?v=4xzVQ8I5bAdpCaXTq6V-pbiazrTDxDcDLLOVK9vFcvA1» rel=«stylesheet»/>
<script src=«/bundles/jquery?v=yRPfz5bh9VSQAkfuQBBn0HqF_TV0k6KYzYy8itNB7gg1»></script>
<script src=«/bundles/jqueryui?v=YAvUtt2TDRGE4OYBGEMX1SClCu75Pv40FoxwBpawyRc1»></script>
<script src=«/bundles/javascript?v=uwcb5jqFGQ51ib9zcRYH09IacFZ_FKjGtEtsxfbLHdw1»></script>
</head>
Я конечно понимаю, что у Вас нет интереса к своему детищу. Но и полностью переделывать не прошу. Прошу лишь направить в правильном направлении.
По сути нужно перекомпоновать готовый код, чтобы он запускал из консоли браузера и не требовал подгрузки внешнего файла, а текст из файла просто ручками добавить в качестве массива. Но никак не пойму чем и как заменить функцию подгрузки внешнего файла на массив правильного формата.
Спасибо, вас тоже с праздниками! ?
Утилита написана на Гоу, она не может запускаться в консоли браузера, там нужен другой язык программирования. Когда я смотрел в последний раз, что они там переделали, у меня сложилось впечатление, что мою утилиту нужно будет писать с нуля, прежний способ работать не будет.
Насколько я понял, Хром прекрасно понимает язык Go. Тем более, что синтаксис очень похож на JS. При запуске из консоли ошибки появились как раз на этапе подгрузки внешнего файла.
Нет, ни один браузер не понимает язык Гоу. Выше, в этой статье, кусок на Джаваскрипте — он готовит ссылки для скачивания, вы видимо именно его копируете. Переписывать надо и его, и программу, которая скачивает (вот она как раз на Гоу написана).
Заставил работать скрипт для ГАВО, изменив эти строки:
```
var imgs = $(’div.img-pnl img[src*=Pages]:first’);
if (imgs && imgs[0]) {
var page = imgs[0].src.match(/Id=([^&]+)/)[1];
```
т. е. поменял селектор для imgs, вместо переменной id использовал «div.img-pnl», а в src в ГАВО Id пишется с заглавной.
Кто-нибудь ковырялся с содержимым, закодировнным в base64? внутри бинарные данные, нужно поковыряться в них. Обходить все страницы дела, собирай айдишники — это костыль :/
Еще одна мысль — нужно брать со страницы имена файлов и использовать их. Сделать опцию для выбора имени файла — оригинальное либо сквозная нумерация, как сейчас.
В общем, сделал вывод «ld : Название файла.jpg»
```
!function () {
var id = ’[id=storageFilesViewerPnl]’;
var bt = ’[id$=ForwardBtn]’;
var pages = {};
var o = document.querySelector(id);
!function _observe(undefined) {
var ob = new MutationObserver(function() {
console.log(«mutator!»)
var imgs = $(’div.img-pnl img[src*=Pages]:first’);
if (imgs && imgs[0]) {
var page = imgs[0].src.match(/Id=([^&]+)/)[1];
console.log(page)
if (pages[page] == undefined) {
var title = $(’input#MainPlaceHolder__storageViewerControl__storageFilesViewerControl_FilesDropDownList_I’).val()
console.log(«Title:» + title)
pages[page] = page + « : » + title;
var next = $(bt);
if (next && next[0]) {
next[0].click();
} else {
ob.disconnect();
console.clear();
console.log(Object.values(pages).join(«\n»));
}
}
}
});
ob.observe(o, { childList: true, attributes: true, subtree: true, attributeFilter: [’src’] });
}();
o.setAttribute(’src’, true);
}();
```
Результирующий файл обхожу скриптом на Perl (пока так, мне на перле быстрее всего мокапить)
```
#!/usr/bin/env perl
while (<>) {
m/^([\w-]+) : (.+)/ && do {
print «$1: $2\n»;
`curl -sS -C —
retry 5output ’$2’ ’http://gavo.arsvo.ru:8082/Pages/ImageFilePart.ashx?Zoom=1&Id=$1’`;}
}
```
Слушайте, ну вы же видите, что маркдаун не работает, зачем же упорствуете? )
Чтобы можно было видеть разметку и представлять как красиво это могло бы выглядеть )) Вдруг заработает — а мы готовы
Илья (ведущий автор движка блога) слишком не любит маркдаун, чтобы это тут заработало )
Кто нибудь решил проблему со скачиванием из архива?
Кому нужен софт, скачивающий с АИСа — пишите в личку в ВК.