
Производительность различных библиотек регулярных выражений
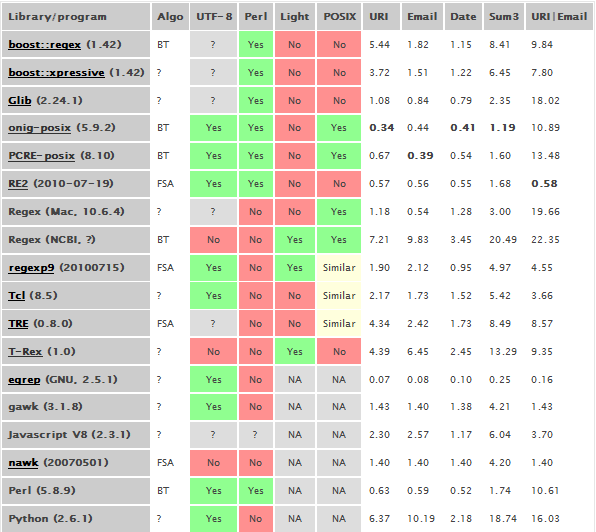 |
Много читал с утра о библиотеках регулярных выражений. Хочется найти такую, чтобы работала с UTF-8, была быстрой и мощной. Без особой надежды поискал в интернете обзоры библиотек и нашёл статью «Benchmark of Regex Libraries».
Автор сравнивает по скорости обработки три регулярных выражения, правда довольно несложных, на приличного объёма тексте. Но даже и на этих несложных регулярках есть явные аутсайдеры — например, Python (хотя другие тесты дают другие результаты).
Жалко автор не составил такую же таблицу для режима UTF-8, там производительность может сильно отличаться.
Например, мне из таблицы понравилась библиотека RE2, она показывает хорошие результаты, при этом в последнем тесте вырывается далеко вперёд. Правда в ней не реализована часть синтаксиса (например, нет backreferences), но это я бы пережил. А вот насколько она эффективная в режиме UTF-8 — вопрос (вопрос тем более актуален, что библиотека показывает примерно равную с PCRE эффективность, а PCRE с UTF-8 работает медленно).
Кстати, скрипты для тестирования доступны для скачивания. Можно попробовать переключить пару библиотек в UTF-8 и посмотреть что с ними будет.
Добавлено позднее: раз доступны скрипты тестирования, я решил посмотреть не находится ли уже RE2 в режиме UTF-8 (у неё это режим по-умолчанию), оказалось, что находится:
RE2 p(argv[1]);
buf = (char*)calloc(BUF_SIZE, 1);
while (fgets(buf, BUF_SIZE - 1, stdin)) {
++l;
for (q = buf; *q; ++q); if (q > buf) *(q-1) = 0;
if (RE2::PartialMatch(buf, p))
printf("%d:%sn", l, buf);
}
free(buf);Чтобы выключить режим UTF-8, нужно использовать константу RE2::Latin1, а её в коде нет. Значит, RE2 работает в режиме UTF-8. Интерееесно.
А почему RE2 вырывается далеко вперёд, по-моему, у egrep результаты лучше.
Комментарий для Максим:
egrep, во-первых, не библиотека, во-вторых, возможности этой утилиты крайне скромны.
https://github.com/dprokoptsev/pire — смотрел?
я для юникода обычно использую oniguruma. она в php прячется в mb_ereg
она и тут в рейтинге даёт наибольшее количество самых быстрых результатов
Комментарий для voldmar.ru:
Не подходит под слово «мощная».
Комментарий для indeyets.ru:
Я почему-то не смог заставить там работать \p{L} и им подобные конструкции. Ведёт себя так, как будто ошибка в регулярном выражении.
Я пытался скомпилировать тесты для re2, но по логам увидел, что это плохая идея — там всюду используется pthreads, а с thread safe у PHP всё неоднозначно.
Комментарий для indeyets.ru:
Та версия, которая в PHP 5.3.2 работает как-то неадекватно:
thasonic-dev ~ $ php -r ’mb_regex_encoding(«Utf-8»);var_dump(mb_eregi(«z», «ЯZ»));’
int(1)
thasonic-dev ~ $ php -r ’mb_regex_encoding(«Utf-8»);var_dump(mb_eregi(«я», «ЯZ»));’
bool(false)
thasonic-dev ~ $ php -r ’mb_regex_encoding(«Utf-8»);var_dump(mb_eregi(«\p{L}», «ЯZ»));’
bool(false)
thasonic-dev ~ $ php -r ’mb_regex_encoding(«Utf-8»);var_dump(mb_eregi(«^:upper:+$», «ЯZ»));’
int(1)
То есть какие-то части работают, другие — нет. Но с этим можно попробовать мириться.
Видимо, потому что в PHP 5.3.2 вкомпилена версия 4.7.1: