
Что за проект я перевожу на UTF: FAQ
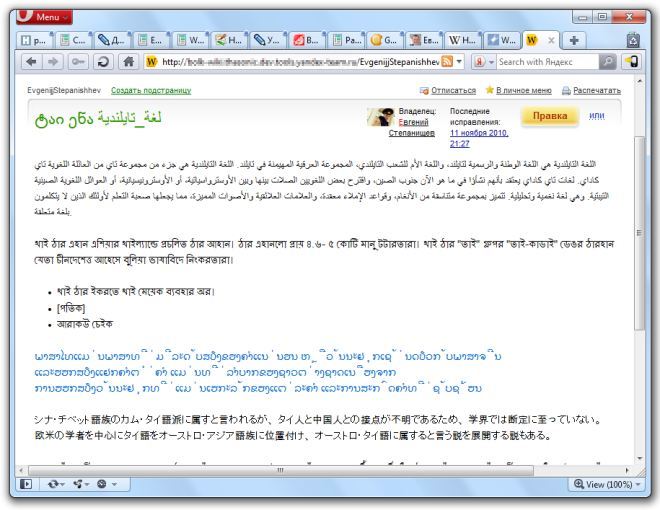 |
Из комментариев на одном из сайтов Димы видно, что люди делают какие-то совершенно дикие выводы относительно моей эпической борьбы с UTF-8 в PHP. Кстати, она окончена, остались мелочи, доделки и доводки. На скриншоте — уже бета.
Так что небольшое FAQ.
В: Долго ещё до конца сериала? О: Следующая часть будет последней.
B: Что за проект переводится на UTF-8? О: Это внутренняя Вики, основанная на ВаккоВики, дописанная за годы использования и интегрированная с остальными внутренними сервисами. Её нередко можно встретить на слайдах презентаций «Яндекса».
B: Зачем переводится? О: Все остальные внутренние сервисы «Яндекса» на UTF-8, что делает задачу интеграции Вики иногда чрезвычайно сложной, кроме того, есть большая потребность научить нашу Вики работать не только с русскими и английским, но и с другими языками.
B: Нельзя ли переписать это всё на другой язык, где нет проблем с UTF-8? О: Можно, но это человеко-годы, я справился намного быстрее.
В: Зачем нужно было всё автоматизировать? О: Во-первых, автоматизированно было далеко не всё, некоторые места я искал в автоматическом режиме, а изменения приходилось вносить руками, во-вторых, всего было сделано несколько тысяч замен, можно ли такое количество заменить вручную, да ещё и не ошибиться?
В: Почему бы нанять сотню студентов, за копейки, чтобы они сделали замены руками? О: За этими студентами нужно проверять работу, кто это будет делать? Я за собой вычитывал исходники, распечатывал листы diff’ов, уходил куда-нибудь в переговорку и работал с бумажками — выделял карандашом проблемные места, потом новая итерация. Со скриптом проще — в одинаковых ситуациях он споткнётся одинаково, сотня студентов споткнётся сотней разных способов.
В данном случае я соглашусь, что проще было переписать это всё в Вики 2.0
И даже не из-за UTF.
Я распознал на скриншоте арабский, тайский (вроде) и японский. А что между арабским и тайским?
грузинский.
Болк, не планируешь все посты объединить в статью?
Я могу оценить титанический труд, проделанный автором, но эта серия постов для меня — последний гвоздь в крышку PHP. То есть я, конечно воспользуюсь им, если это будет необходимо по работе, но по собственной воле — никогда.
*возвращается к написанию многоэтажных «SQL запросов» на Bash*
P.S. Может, я что-то пропустил, но почему был выбран именно UTF8, а не просто несжатый юникод?
Погоди, а как проблема с utf-8 решена в mediawiki?
Комментарий для Zverik:
Длинноватая статья получится :) Её осилят единицы :) Разве что оглавление вынести.
Комментарий для sad-wind.ya.ru:
То, что они (авторы языка) настолько протянули с Unicode, совершенно не делает им чести. Поддержка Unicode сейчас уже необходимость. Мы тоже всё новое пишем исключительно на Python.
Нам просто всё равно. Но так как наружу всё равно отдавать UTF-8, выбрали его.
Комментарий для vladon.ru:
Навалились всем могучим сообществом и решили, думаю так.
Комментарий для mkal.livejournal.com:
Идут: арабский, санскрит, лаосский. Под японским идут хвосты тайского, но его почти не видно.
Заголовок это две кодировки: грузинский и арабский.
Комментарий для sad-wind.ya.ru:
Так вроде и в руби тоже есть проблемы с utf-8 и тамдаже конфликт на этой почве с отцом-основателем...
а в python все хорошо? символ по индексу в utf-8 строке ищется?
Комментарий для fantaseour.ya.ru:
В Python всё хорошо. Есть два типа строк — str (строка в однобайтной кодировке) и unicode (строка в Unicode). Всё, что есть в языке, в основном, понимает оба типа строк.
Выглядят они просто:
string = ’hi!’ — это строка str
string = u’لغة تايلندية’ — это строка unicode (начинается с «u»)
string[1] в обоих случаях вернёт правильный символ.
Преобразовать одну строку в другую легко. Ну, конечно, если unicode попытаться преобразовать во что-то однобайтное, может не получиться из-за отсутствия необходимых символов.
Комментарий для Евгения Степанищева:
<blockquote>Навалились всем могучим сообществом и решили, думаю так.</blockquote>
А почему не взял их решение, а написал своё?
Комментарий для vladon.ru:
Ок, распишу. Правда, мне эта идея кажется странной. Что-то вроде «— моя Хонда тут застрял // — А почему вы не ездите на БеЛАЗе?»
В-первых, это совершенно разные приложения, это был бы огромной потерей времени для всей компании — переучить 2000+ человек пользоваться другой программой.
Во-вторых, абсолютно разный язык разметки. Нужно сконвертировать десятки тысяч документов, плюс их ревизии. Одна разработка парсера существующей разметки с переводом её в (совершенно несовместимую) разметку MediaWiki — очень сложная задача.
В-третьих, у нас очень богатая интеграция с остальными внутренними сервисами.
В-четвёртых, сейчас мы знаем (хоть и не всегда чётко, некоторые куски мы не трогали) как устроена наша Вики, следовательно мы довольно быстро (по мере сил) реагируем на баги и внедряем необходимое. В MediaWiki нужно ещё разобраться.
В-пятых, есть определённые шаблоны использования нашей Вики, поддерживаются ли они в MediaWiki? Большой вопрос. Можно ли их туда внедрить? Тоже вопрос.
Думаю, если напрягусь, я вспомню ещё 2-3 причины, но и этих должно быть достаточно, не так ли?
Комментарий для Евгения Степанищева:
нет-нет, я имел в виду не замену самой вики, а просто взять оттуда модуль работы с utf-8
Комментарий для vladon.ru:
А зачем он мне? Самый главный труд — это замены обычных вызовов на UTF-8-совместимые вызовы.
Комментарий для mkal.livejournal.com:
Бенгалор
Комментарий для Евгения Степанищева:
А свои добавления и исправления в http://wackowiki.org сливали? Это которая «wackowiki.org R4.4.rc1 -> feature freeze» сегодня.
Комментарий для etz:
Конечно нет. Наша Вики только основана на WackoWiki. За годы от той версии мало что осталось. Скоро, например, полностью будет переписан вики-парсер.
Комментарий для Евгения Степанищева:
Не нашёл оглавления, надёргал сам. Положи куда-нибудь на память потомкам)
Комментарий для razetdinov.ya.ru:
Спасибо, но вот же: http://bolknote.ru/write/?issue_phputf8 :)
Комментарий для Евгения Степанищева:
Мда, минут опять ушло, чтобы найти эту ссылку на сайте :)