
Капча и архивы
Я работаю в компании, которая производит своё решение для электронного документооборота и много лет назад мне пришла в голову идея, относящаяся к нему, которая так и не пригодилась. Она мне до сих пор нравится, поэтому хочу ей поделиться.
Если вкратце, то кроме печатных документов в документообороте разными путями оказываются и рукописные тексты — в основном их пишут граждане, но это могут быть регистрационные или другие пометки на документах пришедших на бумаге.
Несмотря, что сейчас есть решения, сносно распознающие рукописный текст, но человек с этой задачей, всё-таки, справляется гораздо лучше.
Идея было в том, чтобы показывать рукописные кусочки этих документов людям как капчу или для подтверждения каких-либо необратимых действий (как правило — удаления чего-либо из системы). Фокус в том, что показывать надо два фрагмента — известный и нет, а неизвестную часть показать несколько раз разным людям. Таким образом по известной части можно определить, что это не робот, а неизвестная переведётся в текст.
В прошлом «Гугл» и «Яндекс» уже распознавали таким образом куски печатного текста и номера домов, почему бы то же самое не сделать с рукописным текстом? Тем более у «Яндекса» есть прекрасный, очень нужный сервис «Поиск по архивам», позволяющий искать по автоматически распознанному тексту. Можно было бы улучшить качество распознанного текста за счёт капчи.
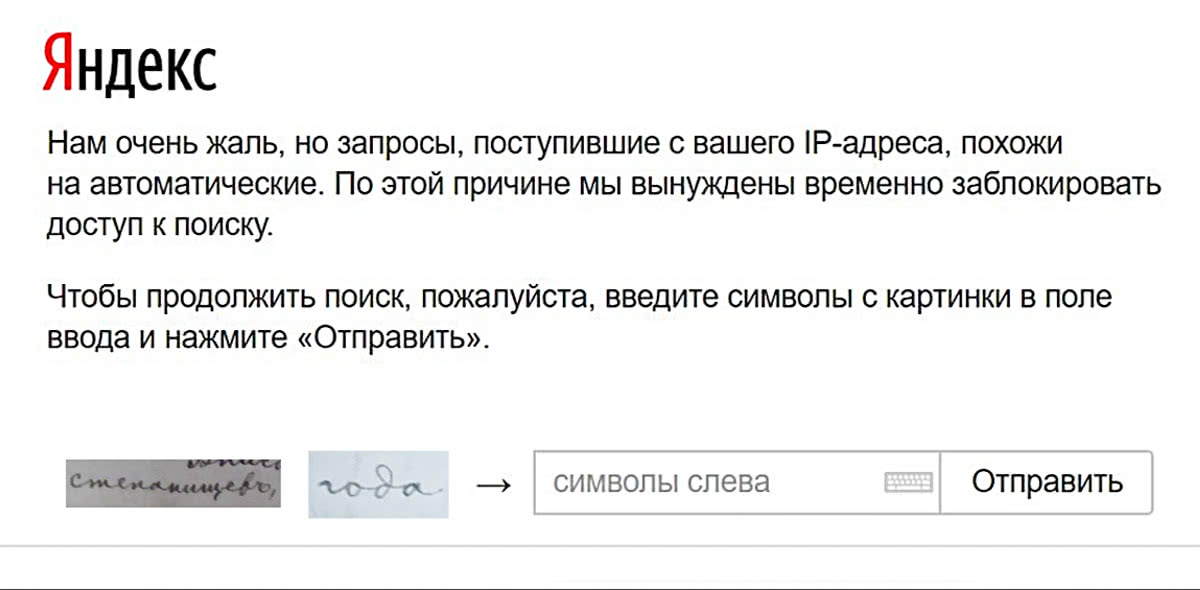
С таким замыслом была сделана recaptcha. И вот эта гуглевская штучка «отметьте все светофоры на картинке» . Кажется, от этого отказались из-за спама/автоматических решалок капчи, и кажется сейчас все эти штуки просто определяют что человек живой подсовывая сложные задачки с известным им ответом и замеряя тайминги (но это не точно)
Я про это тоже пишу:
Автоматические решалки пока очень плохо решают рукописные тексты. В поиске по архивам Яндекса можно посмотреть уровень распознавания. Это лучшее, что есть.
Инглип одобряет)
Боюсь что это будет большой проблемой для людей, отвыкших от рукописных текстов. Сейчас это большинство пользователей интернетов. К тому же, если говорить про дореформенную орфографию, есть ряд ныне неиспользуемых букв, да и орфография непривычна. В итоге каптча будет не столько защищать сайт от роботов, сколько ограждать от пользователей.
С дореволюционной проблема, согласен… тем более рукописная «ѣ» пишется достаточно неожиданным образом.