
Программа CSV SQL Monitor
Некоторое время назад, испробовав различные программы для обработки логов Squid, я убедился, что ни одна из них не отвечает моим требованиям и написал свою. Простенький, однозадачный вариант на языке Perl. В качестве базы данных я выбрал модуль для Perl, который позволяет делать SQL-запросы к файлу в формате CSV (Comma Separated Values).
Это уже потом я узнал, что в CSV SQL нет агрегатных функций, LIMIT, да и скорость работы модуля оставляет желать лучшего и переписал всё с использованием DB_File::Lock и fork. Но от времён, когда я использовал CSV у меня осталась программа, которую я написал для удобства работы с SQL-запросами.
Назвал я её незатейливо — CSV SQL monitor, текущая версия 1.06. Возможно, кому-то пригодится, мало ли какие задачи придётся решать.
Итак, CSV SQL monitor. Для функционирования требуются модули Term::ReadLine (лучше Term::ReadLine::Gnu), Text::Tabs, Cwd, DBI и DBD::CSV. При запуске можно указать необязательный параметр — местоположение каталога с CSV-файлами, если этот параметр не указан этим этим каталогом считается рабочий каталог программы. Все файлы в нём считаются таблицами, к которым, при ограничениях описанных ниже, можно делать запросы.
SQL-команды полностью идентичны обычному SQL за исключением накладываемых модулем DBD::CSV ограничений. В мониторе вместе с SELECT-запросом можно использоваться LIMIT — его я эмулирую, пропуская и возвращая указанное число строк. LIMIT работает в режиме MySQL, т. е. команда
SELECT * FROM file LIMIT 1,2Пропустив одну, покажет две строки, с условием, конечно, что в файле есть хотя бы 3 строки данных. Кроме того, я реализовал ряд специфических команд, которые позволяют получить кое-какую информацию или сконфигурировать модуль DBD::CSV по своему усмотрению:
SHOW TABLES
Показывает имена «таблиц» в каталоге, указанном как каталог с CSV-файлами.
BIND TABLE <имя таблицы> <имя файла>
Так как файлы у вас могут называться как угодно (например, «my document.csv»), а SQL не допускает использование имен таблиц с пробелами, точками и другими подобными символами, но использовать эти файлы в качестве таблиц всё равно нужно, Monitor позволяет «привязать» к «неудобному» имени любое другое, которые SQL примет как удовлетворяющее стандартам.
BIND TABLE log log.txt
VAR FOR <имя таблицы> <имя переменной > <значение переменной>
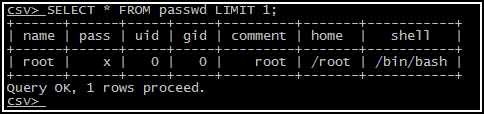
Позволяет настроить некоторые специфические параметры для таблиц, например, символ, который будет считаться разделителем строк или полей. Подробнее о значении каждого параметра можно прочитать в документации по DBD::CSV, а я лишь приведу пример, который позволит понять, каким образом удалось получить картинку, как не скриншоте.
Я использовал три команды:
VAR FOR passwd eol \\n
VAR FOR passwd sep_char :
VAR FOR passwd col_names name,pass,uid,gid,comment,home,shell
После чего, можно спокойно назначать каталог /etc рабочим и делать запросы к таблице passwd (для людей, не знакомых с Unix, сделаю пояснение: в файле /etc/passwd Unix, в традиционной конфигурации, хранит основные данные о пользователях). Если требуется удалить какое-либо значение, можно просто ввести undef вместо значения переменной.
Кстати, отсюда можно увидеть, что все экранирующие слеши (\) должны быть экранированы таким же слешем, чтобы отличать случаи их упоминания от специальных команд, речь о которых пойдет ниже.
Специальные команды нужны, чтобы сообщить «Монитору», что именно вы хотите, чтобы он сделал. Думаю, они будут хорошо знакомы всем, кто хотя бы раз использовал mysql-монитор, работающий из командной строки. Специальные команды используются либо в конце SQL-запроса, либо сами по себе, для выполнения каких-либо действий. Все они (кроме ;) начинаются с экранирующего слеша.
Примеры использования специальных команд:
SHOW TABLES\G
\r /etc
Полный список этих команд вы, в любой момент, можете получить командами \? или \h, я приведу их тут с подробной расшифровкой их действия.
\h или \? — как я уже сказал, позволяет получить список всех доступных специальных команд.
\c — очищает буфер команды. Если вы набрали какую-то SQL-команду, но не запустили её на выполнение, она будет сохраняться в буфере до тех пор, пока вы её не выполните (командами ;, \g или \G) или не очистите буфер командой \c.
\r [<каталог>] — закрывает текущее соединение с каталогом и открывает новое. С аргументом «каталог» действие аналогично команде \u.
\g — выполнить текущий SQL-запрос. Синоним этой команды — ;.
\G — выполнить текущий SQL-запрос и вывести результат вертикально. Что это такое я объяснять не буду — достаточно один раз применить эту команду, чтобы понять о чём идёт речь. :)
\u <каталог> — сменить каталог с CSV-файлами.
\q — выйти из Монитора.
Если вы используете модуль Term::ReadLine::Gnu, вам будет доступны такие возможности как пролистывание команд (стрелки «вверх» и «вниз») и автодополнение команд.
Автодополнение команд я постарался сделать зависимым от контекста. Так, если вы введете S и нажмёте Tab, то получите список из двух команд — SELECT и SHOW TABLES, далее, если ввести ещё и E и нажать Tab строка дополнится до SELECT . В нужном месте Tab выведет вам список файлов в текущей директории, в случае команды VAR FOR покажет список её параметров и так далее.
Конечно, я не учитывал все случаи, но Tab существенно облегчит вам жизнь во многих случаях. Кстати, если вы связали (BIND TABLE) какое-то имя файла с каким-либо именем таблицы, Tab (так же, как и
SHOW TABLES) покажет вам имя таблицы, а не имя файла.
Скачать CSV SQL Monitor можно у меня со страницы. Объём в архиве — 2,8КБ, язык — Perl.
Пишите!