
Непонятный баг с AJAX в IE8
В процессе переезда одного из наших проектов на новый сервер, Интернет Эксплорер восьмой версии стал выдавать какие-то невнятные ошибки при использования AJAX. К решению проблемы подключили меня, так как сообщение об ошибке совершенно не давало ключа к её исправлению:
 |
В этом месте в коде не было ничего криминального, создание объекта для «аякса», асинхронная посылка запроса и проверка свойств того что пришло. Методом проб и ошибок удалось выяснить, что ошибка возникает при попытке обращения к свойствам «status» и «responseText» (а так же «responseXML», в коде он не использовался, но я просто попробовал).
Промучавшись с полчаса, я догадался переключить IE на работу с объектом ActiveX Microsoft.XMLHTTP, вместо XMLHttpRequest, у первого диагностика получше — ему всё-таки много лет, а XMLHttpRequest в восьмой версии браузера тогда ещё не обкатался.
На этот раз я получил нумерную ошибку (скриншота не сохранилось), по номеру которой я нашёл сообщение на сайте Микрософт, что ошибка связана с неверной кодировкой, пришедшей со стороны сервера. В «Хроме» посмотрел кодировку — оказалось, что кодировка с сервера приходит как «cp1251»:
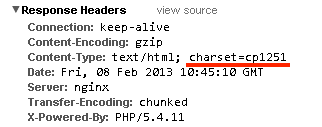 |
Интернет Эксплорер такую кодировку не понял, один из админов вписал её руками, поскольку при смене версии ПХП заменили сервер FastCGI на php-fpm, стоило сменить эту кодировку на «windows-1251» как всё заработало.
Видимо, встретив странную кодировку, IE не смог понять как ему читать то, что пришло, он вообще не заполнил некоторые свойства, а объект, попытавшись получить к ним доступ, не понимал в чём дело и выдавал пустую ошибку, которая и символизировала это «я не понял что произошло».
Ну так-то всё верно, согласно RFC 2854:
charset
The optional parameter «charset» refers to the character
encoding used to represent the HTML document as a sequence of
bytes. Any registered IANA charset may be used [...]
Среди зарегистрированных IANA ( http://www.iana.org/assignments/character-sets/character-sets.xml ) нет такого charset’а (cp1251).
А вообще, я очень удивлён, что на дворе 2013 год, а ваши прогеры до сих пор не осилили utf-8.
Комментарий для vladon.ru:
Посмотрите, для интереса, в какой кодировке «Мой круг» ( http://moikrug.ru )
В чём преимущество перевода нашего продукта на UTF-8? Недостатки я знаю — медленнее всё станет.
Комментарий для Евгения Степанищева:
Надо же. Однако, японцы для МойКруга — не целевая аудитория :)
Комментарий для PastorGL:
Для нас — тоже :)
А ты точно об 8-м экплорере говоришь? А то скриншот похож на windows 8, где оно уже нет, кажется.
Комментарий для o-mokhov.ya.ru:
Скриншот точно Виндоуз 8, в которой запущен ИЕТестер ( http://www.my-debugbar.com/wiki/IETester/HomePage ), в котором я и искал в чём баг. А найден баг был в «оригинальном» IE8 под Windows XP.
Комментарий для Евгения Степанищева:
Комментарий для vladon.ru:
Операции подсчёта длины строки, регулярные выражения, substr и прочие подобные гораздо медленнее, потому что в UTF-8 размер одного символа в байтах варьируется от 1 до 6 байт, а однобайтных строках мне чтобы адресоваться на энтый символ, достаточно адресоваться на энтый байт.
В нашем продукте и это без надобности.
Комментарий для Евгения Степанищева:
Ну можно внутри хранить всё в 1-байтовой кодировке, а выводить, конвертируя в utf-8.
Но в принципе, если необходимости расширяться на более другие языки нет, то действительно незачем.
А разве вы не делаете документооборот для Татарстана? Я даже помню ваша девочка писала, что для Татнефти и правительства РТ.
Комментарий для vladon.ru:
Однобайтовая кодировка — это всего 256 значений. А UTF-8 — это горааааздо больше значений, мне сейчас лень считать сколько, но очевидно же, что в 256 значениях нельзя хранить любое бо́льшие число, так что в чём суть предложения-то?
То, что он у нас в Татарстане используется не говорит о том, что это «документооборот для Татарстана». Например:
http://gov.tuva.ru/news.aspx?id=9221
http://www.tadviser.ru/index.php/%D0%9F%D1%80%D0%BE%D0%B5%D0%BA%D1%82:%D0%90%D0%B4%D0%BC%D0%B8%D0%BD%D0%B8%D1%81%D1%82%D1%80%D0%B0%D1%86%D0%B8%D1%8F_%D0%9F%D1%80%D0%B8%D0%BC%D0%BE%D1%80%D1%81%D0%BA%D0%BE%D0%B3%D0%BE_%D0%BA%D1%80%D0%B0%D1%8F_%28%D0%9F%D1%80%D0%B0%D0%BA%D1%82%D0%B8%D0%BA%D0%B0_%D0%A1%D0%AD%D0%94%29
http://www.cnews.ru/top/2012/04/16/moskva_likvidiruet_sed_luzhkova_25_tys_chinovnikov_otpravlyayut_v_oblaka_485865
Комментарий для vladon.ru:
Я не имею права комментировать планы и стратегии компании.
ой да ладно уж, если остаетесь на моноязычной кодировке, то очевидно, что планов нет...
А потом прибегает задыхающийся пм и изречет — «нам нужна интернационализация!!1».
Очень смешно, на imdb.com стали переводить названия тайтлов по геопризнаку, а вот поискать ничего не выйдет, потому что у них сайт на ISO.
Почти всегда сейчас выгодней начинать сразу на utf-8. Железо дешевеет и становится круче, а зарплата программистам только растет :)
Комментарий для gogis:
У нас, знаете ли, коммерческая организация. Есть цель, есть бюджет, делаем. Именно в таком порядке.
Комментарий для Евгения Степанищева:
Ещё в шестёрке была аяксовая проблема с кодировкой: http://htmlcssjs.ru/JavaScript/?30